Exploring OpenAI's Upcoming Models: Insights and Implications
Written on
Chapter 1: Overview of OpenAI's Strategy
Recent revelations from The Information shed light on OpenAI's strategic direction, particularly the potential for a significant upgrade to ChatGPT this fall. However, this anticipated model may merely serve as a stepping stone toward a more advanced model named Orion, which has only recently been disclosed.
In this analysis, I'll unpack the key elements from The Information's article, which may be somewhat ambiguous, and clarify OpenAI's plans along with the major announcements expected soon.
Stay updated on the latest developments by subscribing to my newsletter, where analysts and strategists find answers to pressing AI-related queries.
TheTechOasis The go-to newsletter for staying ahead in AI
thetechoasis.beehiiv.com
The Reasoning Challenge
The capabilities of Large Language Models (LLMs) are often perceived as enigmatic, but they fundamentally rely on pattern recognition. In essence, these models generate responses based on the data they have encountered during training, leading to a direct relationship between data quality and expected results.
Consequently, these models cannot exhibit behaviors or thoughts they have not previously encountered. Unfortunately, their reasoning abilities are severely restricted, especially when it comes to complex planning or executing intricate tasks due to the lack of relevant data patterns in the training sets.
While many publicly available texts may articulate intelligent conclusions, they typically omit the underlying thought processes. Experts often present their conclusions without detailing how they arrived at them, limiting our frontier AI models to mimic previously observed reasoning outcomes. Thus, the perceived intelligence of models like GPT-4o or Claude 3.5 Sonnet is largely illusory—these systems are adept at interpolating from known data rather than genuinely reasoning through new concepts.
Despite this, the creation of 'intelligent databases' capable of convincingly mimicking human intelligence and compressing vast amounts of information into compact formats is indeed remarkable and immensely beneficial, yet it remains a simulation of true intelligence.
In his foundational work "Computing Machinery and Intelligence," Alan Turing described AI as "The Imitation Game," a definition that remains relevant over seventy years later. This notion, while often disregarded by industry leaders, has been tacitly acknowledged as organizations recognize that LLMs cannot independently develop reasoning skills. To overcome this limitation, the focus must shift to creating reasoning data that allows models to not just imitate high-quality conclusions but also the reasoning processes leading to them.
Synthetic Data: A Double-Edged Sword
Recently, The New York Times highlighted the 'model collapse' issue, where models trained solely on their own outputs may eventually produce repetitive text sequences.
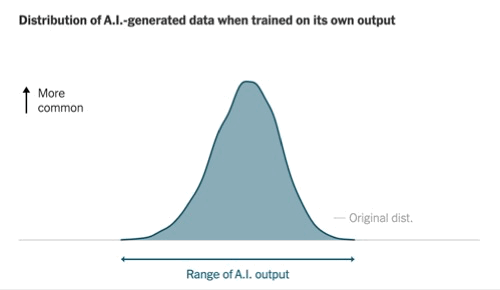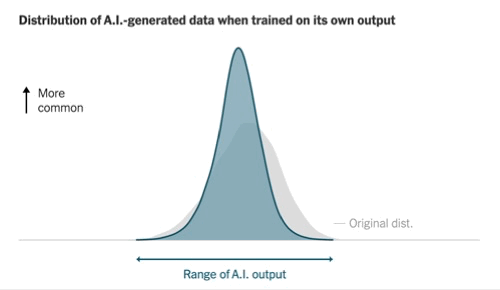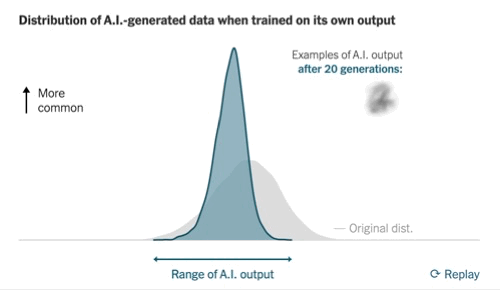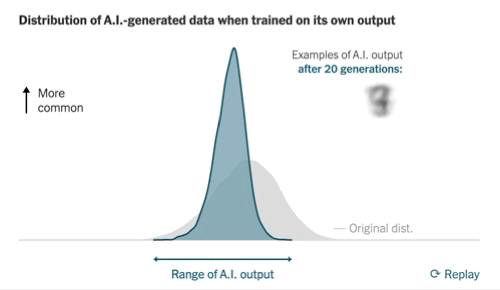
While this perspective is valid, the article underestimates the role of synthetic data, which has been increasingly utilized for training purposes. Numerous models, including GPT-4o and Claude 3.5 Sonnet, have been partially trained on synthetic datasets, with this approach becoming integral to model training processes.
Meta's innovative technique involved checkpointing earlier versions of their models, fine-tuning them with task-specific data such as coding, and using these optimized versions to generate new coding data for more advanced iterations. This method, described by the NY Times as self-training, enhances model performance rather than leading to a collapse in their knowledge.
Furthermore, models can be distilled to create more efficient versions that mimic larger models with a fraction of the computational cost. This distillation process allows for significant performance retention while greatly reducing resource requirements.
Distillation: Enhancing Efficiency
Since the launch of GPT-4 in March 2023, the cost difference with GPT-4o-mini has been striking. GPT-4o-mini is 400 times less expensive than its predecessor for processing a million tokens, while still offering superior performance.
So, how does this work? Distillation involves a unique training approach where the goal is not merely to predict the next word in a sequence but to match the entire distribution of the teacher model. This allows the distilled model to replicate the behavior and style of the original while being trained on synthetic data produced by the larger model.
In practical terms, this means the distilled model learns to generate text that closely resembles that of its predecessor, achieving high-quality outputs without the extensive resource demands typically associated with LLMs.
Chapter 2: The Models on the Horizon
OpenAI’s forthcoming models can be grouped into two distinct families: Strawberry and Orion.
Strawberry: Advancing Reasoning Capabilities
OpenAI has been developing a new model, Strawberry, which aims to significantly enhance reasoning capabilities. Although the exact workings remain partially unclear, existing research offers valuable insights into its development.
In 2021, OpenAI introduced the concept of verifiers—surrogate models that assess the quality of a model's reasoning, which aids in navigating various solutions and enhances performance in reasoning-intensive tasks. This iterative approach increases the likelihood of achieving correct conclusions.
Last year, they published work on process-supervised reward models, which evaluate each step of the model's reasoning process rather than solely focusing on the final output. More recently, the introduction of Prover-verifier games aimed to facilitate clearer answers from robust models, making them easier for weaker models or humans to evaluate.

These advancements collectively suggest that the Strawberry model family will integrate these findings into a single powerful LLM that can thoroughly validate its reasoning steps while being economically viable.
However, given OpenAI's substantial financial losses, a smaller, distilled version of Strawberry may be necessary—one that sacrifices some active search capabilities but retains significant reasoning prowess.
This new iteration, integrated into the ChatGPT product, could provide enhanced reasoning abilities without incurring prohibitive operational costs.
Orion: The Next Frontier
According to The Information, OpenAI may be conceptualizing a synthetic reasoning data generator, Strawberry, to support the development of an even more powerful model, Orion, which is likely to be GPT-5.
Reports suggest this advanced model has already been presented to the US Federal Government, hinting at potential regulatory implications for future AI developments.
In summary, OpenAI might be leveraging instances of GPT-4o to create a vast dataset of foundational reasoning data, employing research insights to craft sophisticated reward models that excel at evaluating reasoning chains. The eventual goal is to train Strawberry Large, which will subsequently be distilled into Strawberry mini, enhancing the ChatGPT experience this fall.
Finally, replicating this process using Strawberry Large could yield Orion, representing the next significant evolution in AI.
A Glimpse into the Future
While speculation remains, the outlined training strategies appear plausible given OpenAI's trajectory. All current models are evolving in similar ways, with OpenAI pushing the boundaries of data utilization and cost-efficiency.
As we ponder the societal implications of such a powerful model, it raises questions about governmental reactions to advancements in AI reasoning capabilities. While current fears may seem exaggerated, the release of a model capable of complex reasoning could shift perceptions dramatically.
In the competitive landscape of AI development, timely releases are critical, and OpenAI's progress will undoubtedly influence the industry's future.
The first video discusses OpenAI's new models, highlighting the implications of recent leaks and innovations in AI technology.
The second video covers the leak of OpenAI's next project, focusing on a new model designed for human-like reasoning abilities.
For business inquiries regarding AI strategy or analysis, please reach out at [email protected].
If you enjoyed this article, I share similar insights on my LinkedIn, where you can follow my work. Alternatively, connect with me on X.