Web Scraping the Highest-Grossing Movies with Python and Selenium
Written on
Understanding Web Scraping
Web scraping refers to the technique of retrieving web pages, extracting valuable data, and organizing that data into a structured format for analysis.
Applications of Web Scraping
Web scraping can serve various purposes, including:
- Price Comparison: Gathering data from e-commerce sites to analyze product prices.
- Real Estate: Creating databases for property listings to support market research.
- Social Media: Collecting trending topics from platforms to gauge public interest.
- Lead Generation: Extracting contact details for potential outreach to customers.
- Movie Reviews: Compiling information about films to determine popularity and ratings.
Is Web Scraping Allowed?
In a 2019 ruling, the US Court of Appeals upheld that publicly accessible data, not covered by copyright, can be scraped, as seen in the case involving LinkedIn and HiQ.
While some websites permit scraping, others restrict it. To check a website's scraping policies, you can append “/robots.txt” to its URL. Additionally, it's wise to read the terms of service before scraping. Excessive requests may lead to an IP ban, but proxies can help circumvent this.
Roadmap for Scraping Movie Data
This article will guide you through a program that scrapes a webpage listing top-earning movies by analyzing the HTML and gathering necessary information. The following steps will be performed using Python and Selenium:
- Install Required Packages and Libraries.
- Set Up the Web Driver.
- Examine the HTML Structure of the Web Page.
- Overview of Selenium Functionality.
- Locate and Extract Data Elements.
- Create and Visualize a Data Frame.
- Export the Data Frame to a CSV File.
The Program
Objective: Extract data elements from a webpage and compile them into a dataset.
Install the Necessary Packages: !pip install selenium
Import Required Libraries: from selenium import webdriver from selenium.webdriver.common.by import By import pandas as pd
Set Up the Web Driver: !apt-get update !apt install chromium-chromedriver
chrome_options = webdriver.ChromeOptions() chrome_options.add_argument('--headless') chrome_options.add_argument('--no-sandbox') chrome_options.add_argument('--disable-dev-shm-usage') driver = webdriver.Chrome('chromedriver', chrome_options=chrome_options) The web driver is essential for Selenium, functioning as a browser automation tool that interacts with web applications.
Examining the HTML Structure
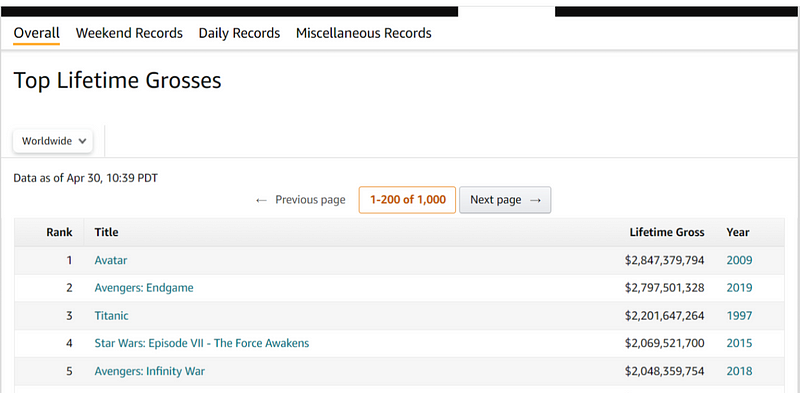
To extract data from this webpage, right-click anywhere on the page, select the HTML arrow icon, and click on the title (e.g., Avatar).
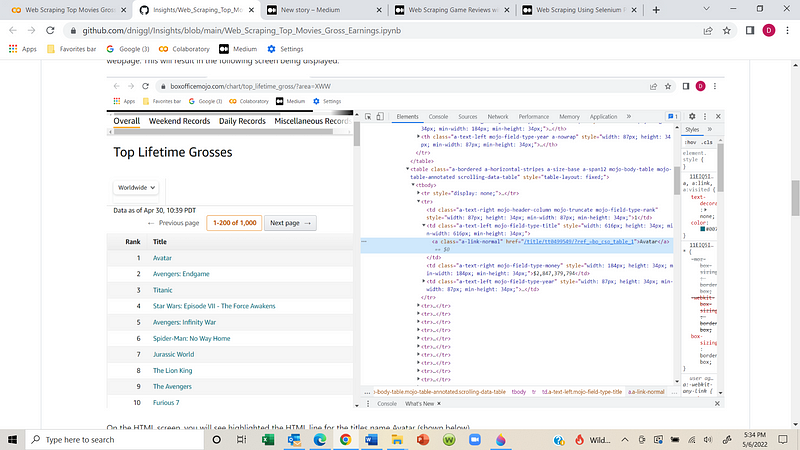
The HTML will display the title's name (e.g., Avatar). By navigating one line up, you can find the parent tag, which is necessary for extracting all movie titles.
Extraction Code Example: movies_names = driver.find_elements(By.XPATH, '//td[@class="a-text-left mojo-field-type-title"]/a[@class="a-link-normal"]')
movie_name_list = [] for movie in range(len(movies_names)):
movie_name_list.append(movies_names[movie].text)
Overview of Selenium
Selenium is a versatile Python library that enables dynamic web scraping and web automation. It offers features such as:
- Multi-Browser Support
- Language Compatibility
- Dynamic Element Handling
- Easy Element Identification
- Performance Efficiency
- Open Source and Portable
Using XPath, a language for locating elements in HTML, we can select data values based on tags and attributes.
XPath Syntax: Xpath = //tagname[@Attribute='Value']
Examples: - Locate all divs with class "movie": Xpath = //div[@class='movie'] - Locate links with class "drama" inside a div: Xpath = //div[@class='movie']/a[@class='drama']
Now, let’s extract essential data from the Box Office Mojo site, including Rank, Title, Lifetime Gross, and Year.
Extracting Data Elements
To extract the desired data, we will find all HTML elements associated with specific tags and classes, store the data in lists, and compile them into a data frame.
Launching the Browser:
Extracting Rankings: movies_rankings = driver.find_elements(By.XPATH, "(//td[@class='a-text-right mojo-header-column mojo-truncate mojo-field-type-rank'])") movie_rank_list = [] for movie in range(len(movies_rankings)):
movie_rank_list.append(movies_rankings[movie].text)
Extracting Movie Names: movies_names = driver.find_elements(By.XPATH, "(//td[@class='a-text-left mojo-field-type-title']/a[@class='a-link-normal'])") movie_name_list = [] for movie in range(len(movies_names)):
movie_name_list.append(movies_names[movie].text)
Extracting Release Years: release_year = driver.find_elements(By.XPATH, "(//td[@class='a-text-left mojo-field-type-year']/a[@class='a-link-normal'])") release_year_list = [] for year in range(len(release_year)):
release_year_list.append(release_year[year].text)
Extracting Lifetime Gross Earnings: lifetime_gross = driver.find_elements(By.XPATH, "(//td[@class='a-text-right mojo-field-type-money'])") lifetime_gross_list = [] for i in range(len(lifetime_gross)):
lifetime_gross_list.append(lifetime_gross[i].text)
Creating and Displaying the Data Frame
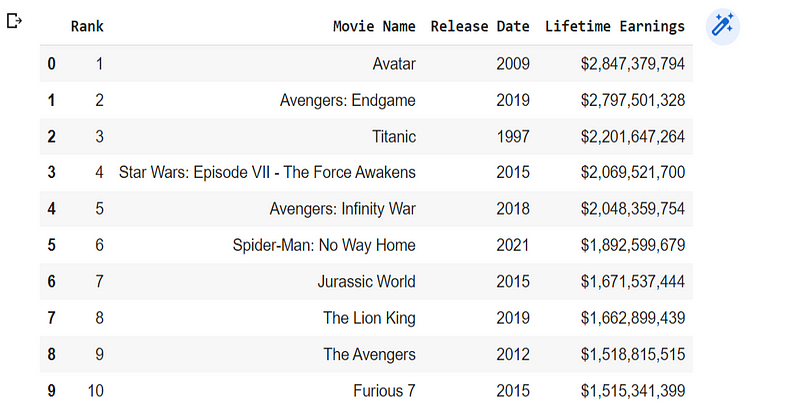
Now we can combine our lists into a data frame and display the results:
data = list(zip(movie_rank_list, movie_name_list, release_year_list, lifetime_gross_list)) df = pd.DataFrame(data, columns=['Rank', 'Movie Name', 'Release Date', 'Lifetime Earnings']) print(df.head(10))
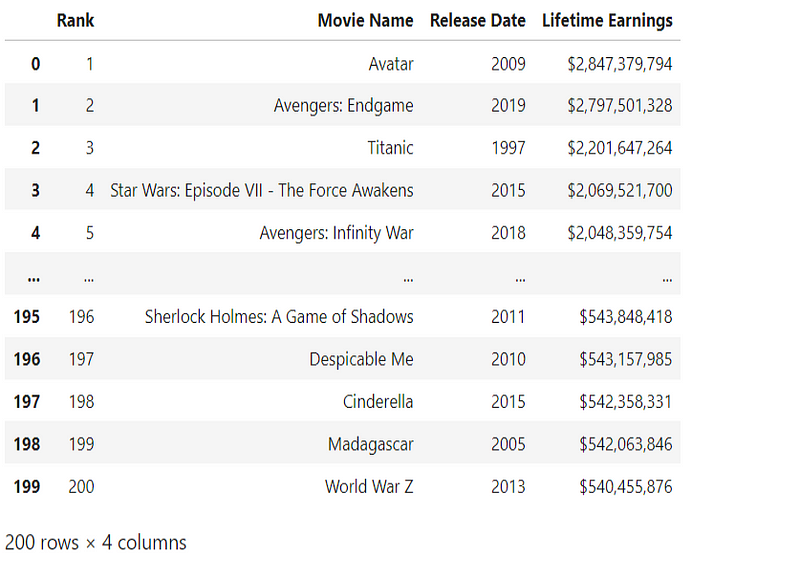
Exporting to a CSV File
To save our data frame as a CSV file, we can execute:
df.to_csv('top_200_movies_with_lifetime_gross.csv', index=False)
You can read back the CSV file with:
reviews = pd.read_csv('top_200_movies_with_lifetime_gross.csv', lineterminator='n')
Video Tutorial: Scraping Data using Beautiful Soup
This video tutorial demonstrates how to scrape data from IMDB's top movies using Beautiful Soup and Python.
Video Tutorial: Browser Automation & Web Scraping with Selenium
This video covers browser automation and web scraping using Selenium and Beautiful Soup.
Thank you for reading! If you have any feedback or questions, feel free to leave a comment below.